
Text-to-image, ook wel bekend als “AI-gegenereerde afbeeldingen” of “tekst naar afbeelding“, is een technologie die kunstmatige intelligentie (AI) gebruikt om afbeeldingen te genereren op basis van een beschrijving in tekst. Bekende AI-tools, zoals DALL-E (van OpenAI), Firefly, Midjourney, Stable Diffusion, Leonardo AI e.d. vallen hier onder. Kort gezegd, Je voert een tekst in en je krijgt vervolgens (na even wachten) een afbeelding op basis van jouw tekst. In dit artikel bekijk ik hoe het werkt en geef ik een vereenvoudigde uitleg, zodat het ook nog eens erg goed te begrijpen is.
Basisdefinitie van text-to-image
Text-to-image is een technologie die kunstmatige intelligentie (AI) gebruikt om tekstbeschrijvingen om te zetten in visuele afbeeldingen. Dit proces omvat het trainen van een AI-model op een enorme dataset van tekstbeschrijvingen en bijbehorende afbeeldingen. Een dataset is een verzameling van gegevens die wordt gebruikt om AI-modellen te trainen. Het getrainde model analyseert vervolgens de inhoud en bedoeling van nieuwe tekst en genereert een afbeelding die past bij de beschrijving. Text-to-image is een krachtig hulpmiddel dat het vermogen van machines om taal te begrijpen en creatief te reageren demonstreert.
Het kan worden gebruikt voor verschillende doeleinden, zoals het maken van illustraties, het visualiseren van data, of het ontwerpen van producten. Het is echter belangrijk op te merken dat text-to-image nog steeds een ontwikkelende technologie is. De gegenereerde afbeeldingen zijn niet altijd perfect of creatief, en de technologie kan soms moeite hebben met complexe of abstracte beschrijvingen.
Een voorbeeld van text to image. Je ziet de afbeelding in een video tot stand komen. Ik heb hier ingegeven:
A futuristic astronaut floats in space, next to a floating rock with a flag, painted in oil in monochrome tones with a hint of red, with a close-up composition that emphasizes the grandeur and loneliness of the moon.Hoe werkt het? Een vereenvoudigd voorbeeld van text-to-image
- Invoer: Je geeft een tekstbeschrijving, ook wel een prompt genoemd, aan het AI-model. Dit kan een eenvoudige zin zijn zoals een kat op een skateboard of een gedetailleerde paragraaf met specificaties over stijl, kleuren en compositie, zoals: pink sunglasses, black ears, a dog in pixar style, cartoon style.
- Begrijpen: Het AI-model analyseert de prompt om de betekenis en nuances van de tekst te begrijpen. Het let op details zoals objecten, acties, locaties, emoties en stijlen.
- Genereren: Het AI-model gebruikt zijn kennis van afbeeldingen en taal om een nieuwe afbeelding te genereren die overeenkomt met de beschrijving. Het doet dit door een complex algoritme toe te passen dat rekening houdt met factoren zoals patroonherkenning, semantiek en visuele compositie.
- Itereren: Het AI-model kan de afbeelding meerdere keren verfijnen om deze te verbeteren en dichter bij de prompt te brengen. Dit proces kan herhaald worden totdat het model een afbeelding heeft gegenereerd die voldoet aan de specificaties.
- Uitvoer: De uiteindelijke afbeelding wordt aan de gebruiker gepresenteerd.
Gegevensverzameling: op basis van datasets
AI-modellen leren van grote datasets die bestaan uit tekstbeschrijvingen en bijbehorende afbeeldingen. Deze gegevens zijn essentieel omdat ze de AI helpen te begrijpen hoe woorden gekoppeld zijn aan visuele inhoud.
Tekstcodering
De tekst wordt eerst omgezet in een numerieke vorm die het AI-model kan begrijpen. Dit gebeurt door middel van technieken zoals woordembeddings of geavanceerdere modellen zoals transformers.
Architectuur van het neurale netwerk
Het AI-model bestaat meestal uit twee onderdelen: een generator en een discriminator.
- Generator: Dit onderdeel gebruikt de gecodeerde tekst om een afbeelding te creëren die overeenkomt met de tekstbeschrijving.
- Discriminator: Deze beoordeelt de gecreëerde afbeeldingen. Het onderscheidt echte afbeeldingen van gegenereerde afbeeldingen en geeft feedback aan de generator om de kwaliteit te verbeteren.
Een vereenvoudigde uitleg over hoe een GAN werkt
GAN staat voor. Dit is een type AI-model dat wordt gebruikt om afbeeldingen te genereren. Stel je voor dat je een kunstenaar bent die schilderijen wilt maken die niet te onderscheiden zijn van echte schilderijen van beroemde meesters. Je gebruikt hiervoor een speciale techniek:
- Je creëert eerst een nieuw schilderij, in de stijl van de beroemde meester. Dit doe je met behulp van een generator, die een soort kunstmatige patroonherkenner is. Je maakt dus iets nieuws en bedenkt nieuwe concepten. Je kopieert natuurlijk niet letterlijk het schilderij.
- Je laat je nieuwe schilderij beoordelen door een kenner, die fungeert als discriminator. De kenner bekijkt het schilderij en bepaalt of het echt of nep is. De kenner heeft eerder al enorm veel afbeeldingen bekeken van echte schilderijen en stijlen. De discriminator “beoordeelt” niet alleen of een afbeelding echt of nep is, maar leert ook patronen te herkennen die kenmerkend zijn voor echte afbeeldingen.
- Op basis van de feedback van de kenner pas je je techniek aan. Je probeert je generator te verbeteren, zodat deze schilderijen kan creëren die nog moeilijker te onderscheiden zijn van echte schilderijen.
Dit proces van creëren en beoordelen herhaal je steeds opnieuw. Na elke beoordeling is er altijd een winnaar, dus de kenner ziet dat het schilderij nep is (de kenner doet nu niets, maar de generator verandert wel iets), of andersom. Na verloop van tijd leert de generator steeds betere schilderijen te maken, doordat de discriminator steeds scherper wordt in het onderscheiden van echte en nep schilderijen. Totdat de generator zó goed wordt dat het schilderij niet meer van echt is te onderscheiden. Dit is niet altijd het einddoel. Het einddoel kan ook zijn om creatieve en originele beelden te produceren.
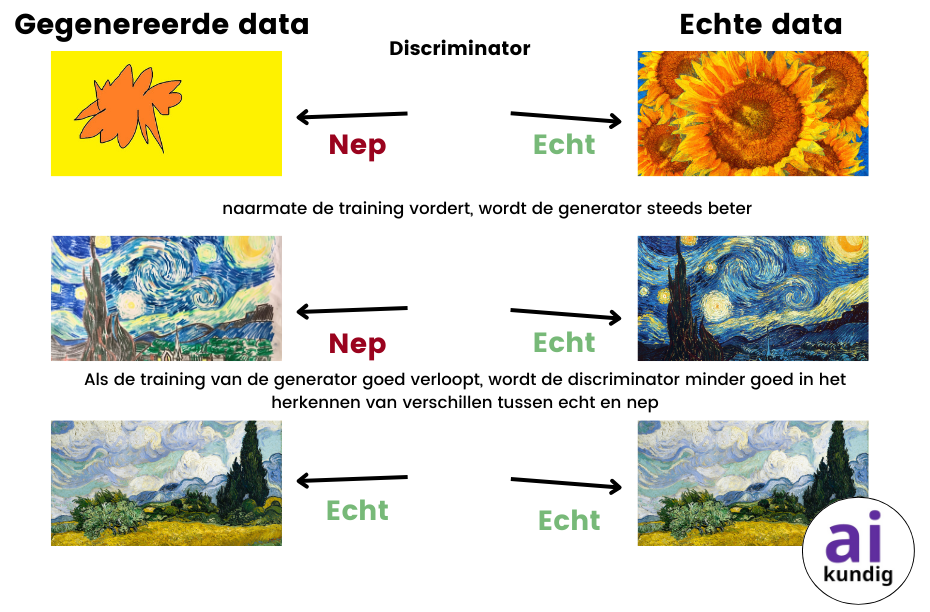
Leuk om te weten: Dit is een voorbeeld van een GAN, een unsupervised learning model.
Trainingsproces
Bij een methode gebaseerd op Generative Adversarial Networks (GANs), worden de generator en discriminator tegelijkertijd getraind. Ze werken tegen elkaar: de generator probeert afbeeldingen te maken die echt lijken, terwijl de discriminator probeert te bepalen of een afbeelding echt of gemaakt is. Deze training gaat door totdat de generator afbeeldingen kan maken die moeilijk te onderscheiden zijn van echte.
Ik was aan het twijfelen om over dit begrip een video te maken op mijn YouTubekanaal, maar ik kan het echt niet beter uitleggen dan IBM doet in de onderstaande video 😊
Goed om te weten: Text-to-image is een toepassing van kunstmatige intelligentie waarbij een AI-model geschreven tekst omzet in visuele afbeeldingen. Dit model leert dit proces door grote datasets met tekstbeschrijvingen en bijbehorende afbeeldingen te analyseren. Door deze voorbeelden begrijpt het hoe woorden en zinnen te vertalen zijn naar beelden. Het is dus geen zelfdenkend systeem, maar een technologie die patronen herkent en toepast die het heeft geleerd uit zijn trainingsdata.
- Onderzoek en ontwikkeling: Wetenschappers en ingenieurs hebben jarenlang gewerkt aan het ontwikkelen van AI-algoritmen en trainingsmethoden die effectief zijn voor text-to-image.
- Dataverzameling: Het samenstellen van grote datasets met tekstbeschrijvingen en bijbehorende afbeeldingen is een tijdrovend en complex proces dat vaak handmatig werk vereist.
- Computationele kracht: De training van text-to-image modellen vereist krachtige computersystemen en toegang tot aanzienlijke rekenkracht.
Afbeeldingen genereren
Als het model getraind is, kun je een tekstbeschrijving invoeren en de generator zal een afbeelding produceren die zo goed mogelijk overeenkomt met die beschrijving. Een voorbeeld zie je in de onderstaande video.
pink sunglasses, black ears, a dog cartoon styleFijnafstemming en nabewerking
Afhankelijk van de toepassing kunnen er extra stappen zoals fijnafstemming of nabewerking worden toegepast om de kwaliteit en samenhang van de gegenereerde afbeeldingen te verbeteren.
Van tekst naar afbeelding: zo pakt AI het aan!
Zoals ik eerder al besprak, is text-to-image een fascinerende technologie die tekst transformeert in visuele kunstwerken. Maar wat gebeurt er precies achter de schermen wanneer je een prompt invoert in een AI-tool?
Vooraf: Hoewel de hier beschreven stappen een helder overzicht bieden van hoe AI tekst omzet in beelden, is het belangrijk om te erkennen dat dit proces afhankelijk is van de specifieke technologieën en algoritmes die worden gebruikt. Bepaalde geavanceerde technieken zoals het toevoegen en verwijderen van ‘noise’ (ruis) tijdens het trainingsproces van sommige AI-modellen kunnen een grote invloed hebben op de kwaliteit en het realisme van de gegenereerde beelden.
De prompt analyseren: De taal ontrafelen
De reis begint met jouw prompt. Je kan dit zien als de sleutel tot het creëren van jouw beoogde afbeelding. AI-tools gebruiken geavanceerde taalmodellen om de tekst te analyseren en te begrijpen.
- Woordbetekenis: Het model breekt de prompt af in afzonderlijke woorden, waarbij de betekenis van elk woord wordt bepaald op basis van context en woordenschatkennis.
- Grammaticale structuur: De grammaticale structuur van de prompt wordt geanalyseerd om de relaties tussen woorden en zinsdelen te begrijpen. Dit helpt het model de volgorde van gebeurtenissen, de interactie tussen objecten en de algehele context van de beschrijving te bepalen.
- Semantiek: AI-tools gaan verder dan woordbetekenis en kijken naar de diepere betekenis van de prompt. Ze identificeren entiteiten (mensen, plaatsen, objecten), emoties, intenties en andere semantische kenmerken die relevant zijn voor de afbeelding.
- Stijl en toon: Sommige prompts bevatten aanwijzingen over de gewenste stijl van de afbeelding, zoals “realistisch”, “schilderachtig” of “dromerig”. Het model houdt rekening met deze stijlaanduidingen om de visuele esthetiek van de afbeelding te bepalen.
Representatie van de prompt: Ideeën in code omzetten
Nadat de computer de tekst heeft geanalyseerd, zet hij deze om in een vorm van code die hij kan verwerken. Dit gebeurt op twee manieren:
- Vectoren: Elk woord of zinsdeel wordt omgezet in een cijferreeks, een vector genoemd, die de betekenis ervan weergeeft. lk getal in de vector vertegenwoordigt een bepaald aspect van de betekenis van het woord. Hier zal ik in dit artikel niet dieper op ingaan, omdat dit anders echt te lang wordt.
- Neurale netwerken: Deze complexe systemen nemen de omgezette tekst (de vectoren) en leren uit de patronen en relaties tussen de woorden om te begrijpen hoe ze er visueel uit moeten zien. Dit helpt de computer om later een afbeelding te maken die past bij de tekst.
A photo of a ginger cat sitting on a windowsill and looking outside. The cat has green eyes and a striped tail. The sun shines through the window, casting a warm light on the cat. The style is realistic, with soft colors and details. --ar 3:2 --v 6.0Afbeelding genereren: Van code naar canvas
Met de prompt in een machine-leesbare vorm, kan het AI-model nu zijn magie uitvoeren en de afbeelding genereren. Dit proces omvat verschillende stappen:
- Beeldvorming: Het model gebruikt geavanceerde algoritmen om een basisschets van de afbeelding te creëren, waarbij rekening wordt gehouden met de elementen uit de prompt (objecten, acties, locatie, enz.).
- Details toevoegen: De afbeelding wordt verfijnd door details toe te voegen, zoals texturen, kleuren, belichting en schaduwen. Het model maakt gebruik van zijn kennis van de echte wereld en visuele principes om een realistische en consistente afbeelding te creëren.
- Stijl overbrengen: De gewenste afbeeldingsstijl (realistisch, cartoon, abstract) wordt toegepast op de afbeelding. Dit kan inhouden dat het model texturen aanpast, kleuren verzadigt of bepaalde details benadrukt.
- Iteratie en verfijning: Het AI-model evalueert de gegenereerde afbeelding continu en voert kleine aanpassingen door om deze te verbeteren en dichter bij de prompt te brengen. Dit herhalende proces kan meerdere keren worden herhaald totdat het model tevreden is met het resultaat.
De uiteindelijke afbeelding: Van digitaal naar zichtbaar
De laatste stap is het presenteren van de gegenereerde afbeelding aan jou. De afbeelding wordt geconverteerd naar een formaat dat je kunt bekijken, zoals JPEG of PNG, en wordt vervolgens op jouw scherm weergegeven.
Enkele belangrijke opmerkingen
Ik wil graag nog toevoegen:
- De kwaliteit van de gegenereerde afbeeldingen kan variëren, afhankelijk van de complexiteit van de prompt, de capaciteiten van het AI-model en de beschikbare trainingsgegevens.
- AI-tools voor text-to-image zijn voortdurend in ontwikkeling en worden steeds geavanceerder in het begrijpen van taal en het genereren van realistische en creatieve afbeeldingen.
- Het is belangrijk om te onthouden dat AI-gegenereerde afbeeldingen geen perfecte weerspiegeling van de realiteit zijn. Ze kunnen onjuistheden, onbedoelde details of vooroordelen bevatten die voortkomen uit de trainingsdata
Niet alle AI-tools werken natuurlijk hetzelfde
In de inleiding schreef ik over de verschillende soorten Text-to-image tools die er op dit moment zijn. Niet elke tool werkt natuurlijk precies zoals in de bovenstaande voorbeelden. Er zijn wel wat overeenkomsten en verschillen.
Overeenkomsten
- Gebruik van geavanceerde AI-modellen: Alle genoemde tools maken gebruik van complexe neurale netwerken en machine learning-algoritmen om tekst te analyseren en afbeeldingen te genereren.
- Analyse van de prompt: De prompt, de tekstbeschrijving van de gewenste afbeelding, wordt in alle tools geanalyseerd om de semantische betekenis, stijl en andere belangrijke kenmerken te begrijpen.
- Generatie van een afbeelding: Op basis van de prompt-analyse genereert het AI-model een afbeelding die overeenkomt met de beschrijving.
- Iteratief verfijningsproces: De meeste tools gebruiken een iteratief proces waarbij de afbeelding continu wordt verfijnd en verbeterd totdat het model een bevredigend resultaat heeft.
Verschillen
- Onderliggende technologie: Verschillende tools gebruiken verschillende neurale netwerkarchitecturen en machine learning-algoritmen. Dit kan leiden tot subtiele verschillen in de stijl van de gegenereerde afbeeldingen en de algehele prestaties.
- Trainingsgegevens: De tools worden getraind op verschillende datasets van afbeeldingen en tekst. De kwaliteit en diversiteit van deze datasets kunnen de kwaliteit van de gegenereerde afbeeldingen beïnvloeden.
- Functionaliteit: Sommige tools bieden extra functies, zoals geavanceerde prompt-instellingen, de mogelijkheid om tussen verschillende stijlen te kiezen of het genereren van verschillende afbeeldingen op basis van één prompt.
- Toegankelijkheid: Sommige tools zijn beschikbaar via webinterfaces, terwijl andere vereisen dat je een app downloadt of code uitvoert.
Veelgestelde vragen en antwoorden over dit onderwerp
Is text-to-image gratis?
De beschikbaarheid van text-to-image tools en hun kosten variëren. Sommige tools, zoals NightCafe Creator, hebben gratis proefperiodes of bieden beperkte gratis functionaliteit aan. Andere tools, zoals DALL-E 2, vereisen een betaald abonnement. Er zijn ook open-source text-to-image tools beschikbaar, maar deze vereisen wel vaak een grote hoeveelheid technische kennis om te installeren en te gebruiken.
Kan ik zelf een text-to-image model trainen?
Het is mogelijk om zelf een text-to-image model te trainen, maar dit vereist geavanceerde technische kennis en veel rekenkracht. Je hebt een grote dataset van afbeeldingen en bijbehorende tekstbeschrijvingen nodig, evenals krachtige computersystemen om het model te trainen. Voor de meeste beginners (en ook gevorderden, zoals ik) is het eenvoudiger om gebruik te maken van bestaande text-to-image tools.
Wat zijn de auteursrechtelijke implicaties van text-to-image?
De auteursrechtelijke implicaties van text-to-image zijn complex en nog volop in ontwikkeling. Het is belangrijk om te weten dat text-to-image modellen worden getraind op datasets van afbeeldingen en tekst die mogelijk auteursrechtelijk beschermd materiaal bevatten. Dit betekent dat de door het model gegenereerde afbeeldingen mogelijk auteursrechtelijk beschermd zijn of inbreuk maken op het auteursrecht van anderen. Het is belangrijk om voorzichtig te zijn met het gebruik van text-to-image voor commerciële doeleinden en om de auteursrechtelijke regels te respecteren.
Wat zijn de ethische kwesties rond text-to-image?
Er zijn verschillende ethische kwesties rond text-to-image, zoals de mogelijkheid om nepnieuws of propaganda te creëren, het gebruik van de technologie om vooroordelen te versterken en – zeker niet te vergeten – de potentiële impact op de creatieve industrie. Het is belangrijk om je bewust te zijn van deze kwesties en om text-to-image op een verantwoorde manier te gebruiken.
Wat is de toekomst van text-to-image?
Text-to-image is een snel ontwikkelende technologie met veel potentiële toepassingen. Naarmate de technologie zich verder ontwikkelt, kunnen we verwachten dat text-to-image tools gebruiksvriendelijker, krachtiger en nauwkeuriger worden. Dit zal leiden tot nieuwe en innovatieve toepassingen in verschillende gebieden, zoals kunst, design, marketing en onderzoek.
Bronnen en meer lezen
- https://en.wikipedia.org/wiki/Text-to-image_model
- https://www.ibm.com/products/watsonx-ai
- https://cloud.google.com/use-cases/text-to-image-ai
- https://openai.com/research/dall-e
- https://www.analyticsvidhya.com/blog/2021/04/generate-your-own-dataset-using-gan/
- https://realpython.com/generative-adversarial-networks/
- https://stability.ai/stable-image
- https://medium.com/@david.gutsch0/the-art-of-embeddings-transforming-text-for-vector-databases-926738443e70
- https://www.linkedin.com/pulse/understanding-vector-databases-powering-world-ai-chris-dougherty/
- https://www.codementor.io/@kalpesh08/how-does-ai-turn-text-into-images-2amzolymx5
- https://developers.google.com/machine-learning/gan/gan_structure